

The Land Grab Data Stack
How we should be using AI with data

It’s 2026, and it’s somehow gotten even worse than it was in 2025. There’s AI all over our data systems, but can I just point out that it seems like no one seems to like any of this? The most celebrated AI data tool I’ve heard of is, embarrassingly, Claude Code (well, it’s not so bad with airlayer). Everything else is “yeah we use it, it’s fine” or the exhausted “no, we haven’t tried it, is it better?” But seriously? Claude Code is not well-suited for a lot of data work (have you tried giving stakeholders raw access?), but people seem to at least be content that it’s not a vendor-locked homunculus.
It’s as though the “sprinkle-some-ML-on-it” PMs from the mid-2010s all had their dreams realized and literally sprinkled AI everywhere, intuiting all of their product sense from VC-speak, then letting things kind of naturally evolve from there. But perhaps “let’s just add an {AI chatbot, AI chatbot v2, agents, context graph, Claude code clone}” may not be a good product idea for every single tool in the space? Because everyone and their grandma seems to be building an AI + context system + semantic layer + etc. into their tool. And it’s not subtle what’s happening — we’re in the land grab era. It’s becoming harder for non-AI companies to fundraise. So everyone is racing to become the system of record for data + AI. Makes sense, but something is really off-putting with what we’ve ended up with: a space where AI is bolted on everywhere, but there is no consensus architecture, there are no open standards, and there is no thread of genuine discussion, even, it seems. Even the newer players are not contributing much — Github feints, case studies, empty promises. Because the only / loudest people talking about this either have too much sunk cost to be able to assess the situation from first principles or, for the newer players, don’t really understand what users want. The donuts look too delicious, forget what’s good for data.

Just look at what’s happened with MCP — it was a wonderful attempt to standardize a protocol and address this. But what we ultimately got is a hub-and-spoke system with toothpick spokes. People aren’t building their MCP integrations in good faith with an eye for architectural solidity, because there’s no incentive to — it’s far better to make the gravity to your platform heavy enough that leaving becomes expensive. The result is a set of nominally interoperable tools that are, in practice, lock-in mechanisms with a standards-compliant veneer.
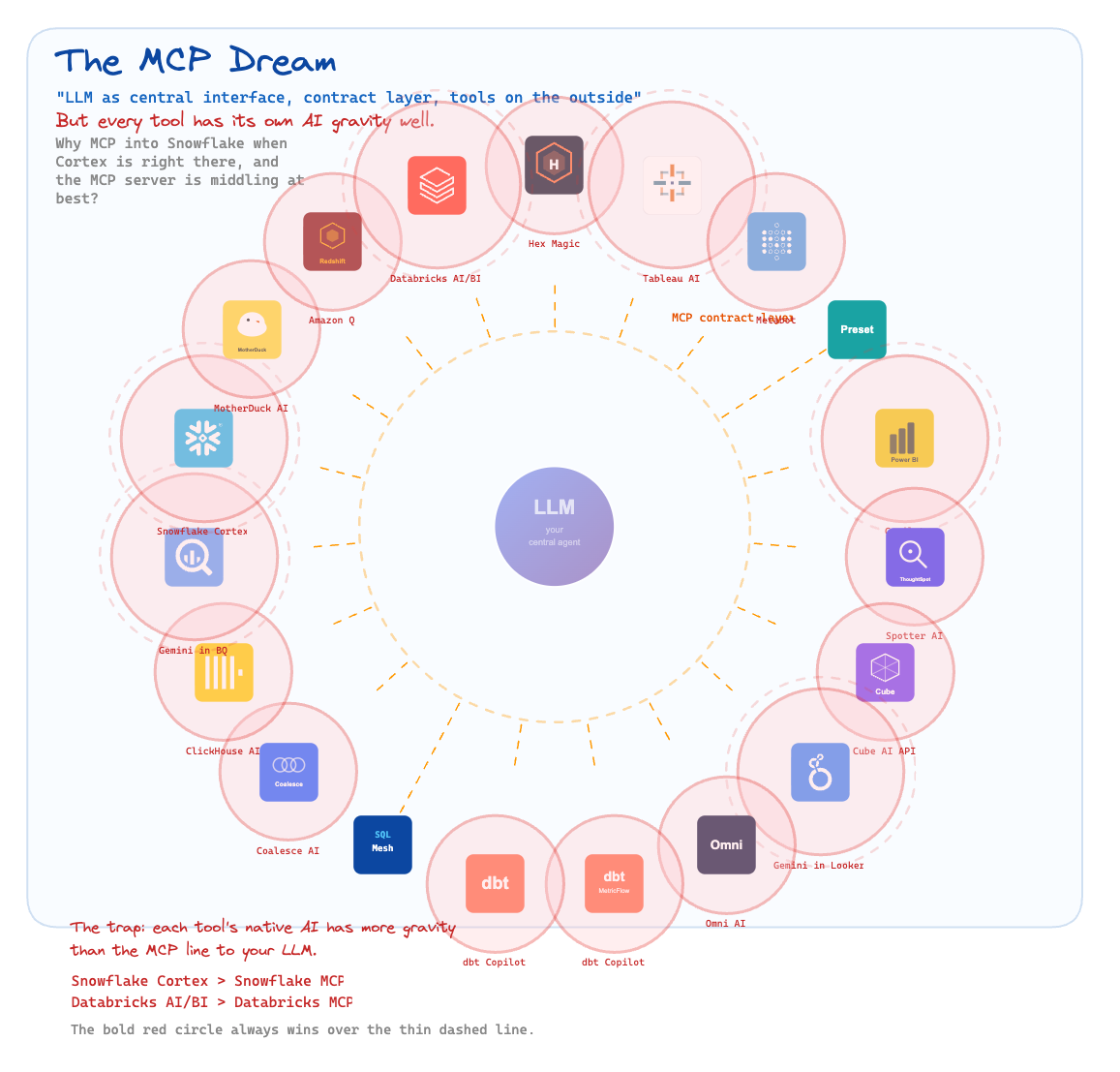
[An attempt at] the correct architecture
To avoid being another old man yelling at clouds, I want to at least open the discussion as to what this should all look like from first principles. Here are the guidelines I’ve come to.
There need to be more utilities, less servers.
CLI + local > MCP + SaaS. Three reasons:
It’s faster. You aren’t gated by network latency, at minimum. But also, you don’t have to finagle through all the cloud barriers like auth tokens, missing API endpoints, rate limits, service outages.
You won’t get price-gouged on network calls. Because MCP requires a server, it enables rent collection and monetization. CLI is better, so long as you avoid the temptation of building a CLI that’s just a thin wrapper over your server.
LLMs work better with local tools. An LLM can call a CLI with structured arguments and parse structured output with near-perfect reliability. They’re just function calls, whereas MCP servers / API-based interfaces introduce connection management, auth state, failure modes that the LLM has to reason around. Simpler interfaces = more reliable agents.
This is the spirit behind airlayer — your semantic layer should be a library call, not a toll booth. But really, none of the tools that an LLM is using should have to be mediated by an external system. This is why Andrej Karpathy’s AI-knowledge base post was so compelling and, at the same time, why Notion AI feels so bad.
There needs to be a testing framework.
You don’t need a testing framework if you’re manually building a system. But if you intend to use AI to build the system, you need tests. This is because harness engineering / Ralph loops / —dangerously-skip-permissions / superpowers / etc. work extremely well, but they only work with a robust testing guardrail. If you have ever tried to overnight vibe code something, you’ll know what I mean — agents drift and tend to make plausible changes that are subtly wrong. You ultimately wake up to a series of changes that compile but don’t actually do what you think they do.
You should always append prompts with “ENSURE ALL TESTS PASS.” Meaning you need tests. Or, of course, you can write all the analytics code yourself, but really?
Everything needs to be configurable and code-native.
In order for a harness to work, it has to attach to parameters of the system that can, in expectation, modify the system such that it can ultimately converge to a state where it produces the correct results. If your data tool’s behavior is hardcoded, or configured through a GUI with no programmatic equivalent, an agent can’t tune it. Configuration-as-code is a prerequisite for AI-assisted modification, not just a devops nicety.
This means: YAML or JSON configs that define behavior. CLI flags that override defaults. Environment variables for deployment-specific settings. Anything that a human clicks through in a UI should have a declarative equivalent that an LLM can read, modify, and validate. Code-native systems (text files, structured configs, CLI tools) are legible to LLMs. GUI-native systems (drag-and-drop dashboards, point-and-click configuration, spreadsheet-based workflows) are opaque. If your tool requires a browser to configure, an LLM can’t reliably operate it.
I tried to get Claude to modify a pre-filled org chart spreadsheet with our actual org chart. It took two hours and spent most of the time trying — and failing — to use browser automation to clear cells with pre-filled data. On the other hand, give an LLM YAML configs to read and modify, and it can do so with perfect fluency.
The land grab ends the same way it always does
The thing about land grabs is that they generally don’t produce good architecture. They optimize for building moats, which are, by definition, obstacles. We went through this with the original modern data stack — composable tools that were supposed to liberate us from vendor lock-in, which then spent a decade re-creating vendor lock-in at every interface (and there are so many interfaces). Now we’re doing the same thing with AI. Every platform is racing to become the “AI layer for data,” and the result is thirty different walled gardens, each with their own context format, their own agent protocol, their own way of representing what a metric is.
The people who will build the lasting systems are the ones who resist the land grab instinct. Open formats. Local-first tools. Testable, configurable, code-native primitives. Not [just] because it’s noble, but because it’s the only architecture that actually compounds — where the agent gets better over time because the system is designed to let it.
The land grab era will end. What’s left standing will be whatever was built on real foundations instead of on the bet that you could lock enough customers in before they noticed.
Entertaining read.
Are there any examples you can point to of tools that are local and non-moated ?